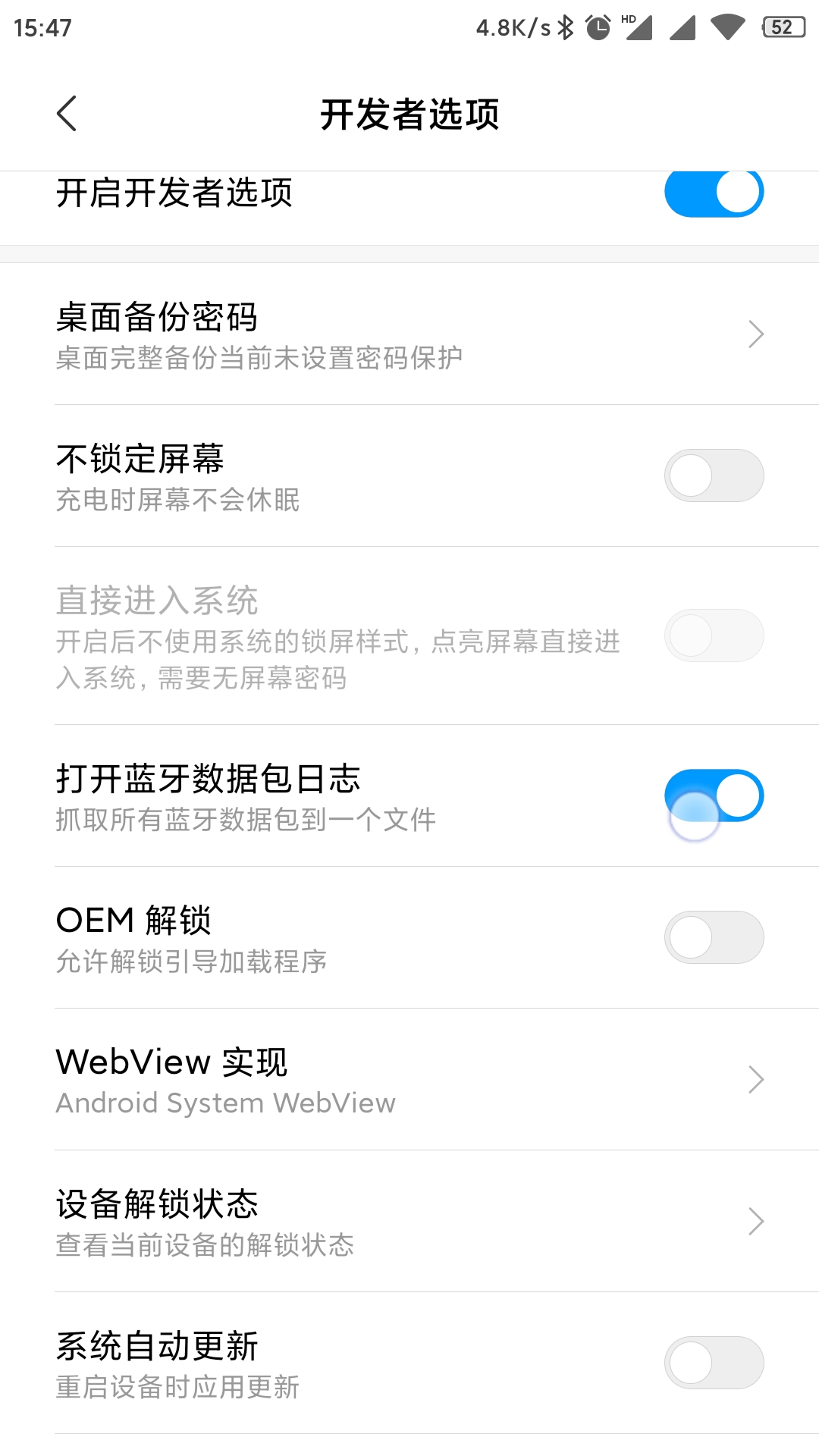
常见寄存器说明
ESP:用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。
EBP:用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。
EIP: 用来存储即将执行的程序指令的地址,CPU依照 EIP 的存储内容读取指令并执行,EIP随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
函数调用时栈区变化
参数逆序入栈
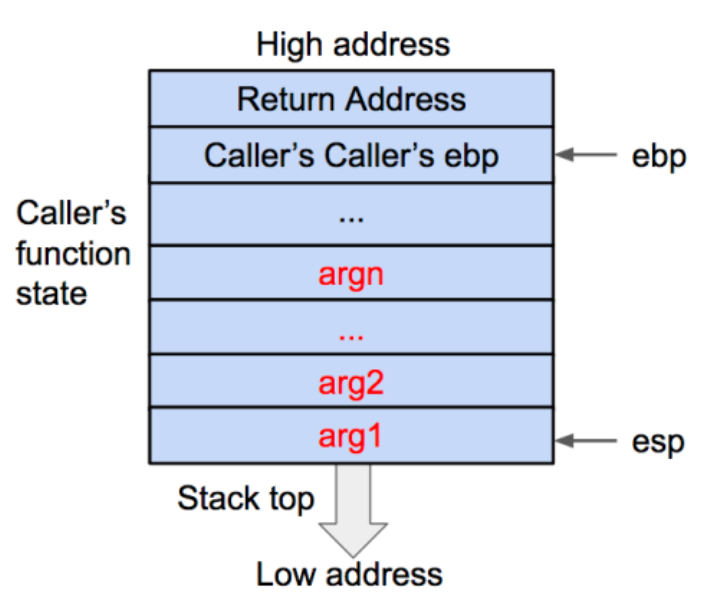
将调用函数(caller)进行调用之后的下一条指令地址作为返回地址压入栈内。这样调用函数(caller)的 EIP(指令)信息得以保存。
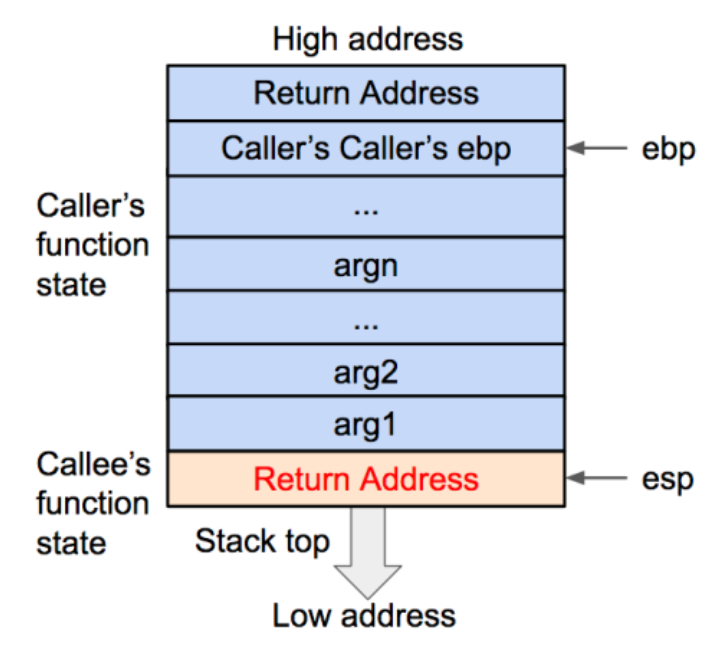
再将当前的EBP 寄存器的值(也就是调用函数的基地址)压入栈内,并将 EBP 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的 EBP (基地址)信息得以保存。同时,EBP 被更新为被调用函数(callee)的基地址。
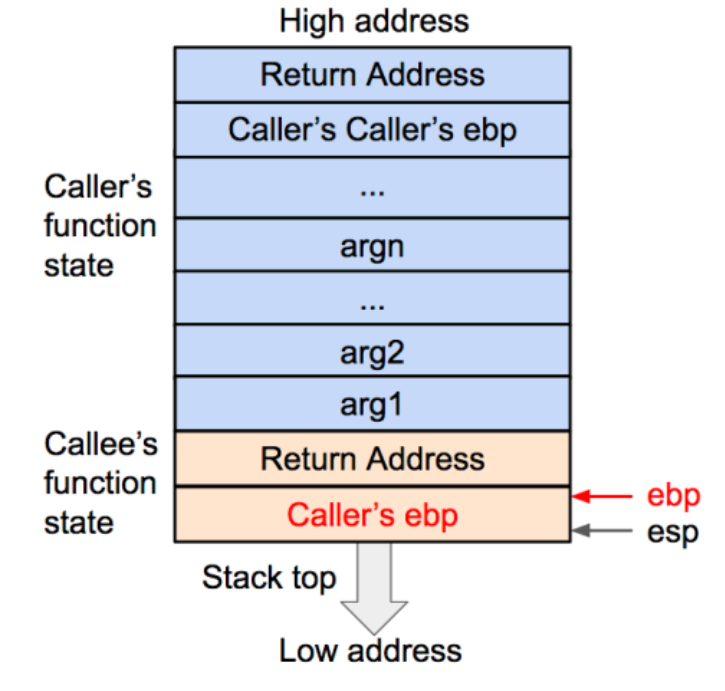
将被调用函数的局部变量压入栈内,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到 eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
看过了函数调用发生时的情况,就不难理解函数调用结束时的变化。变化的核心任务是丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。
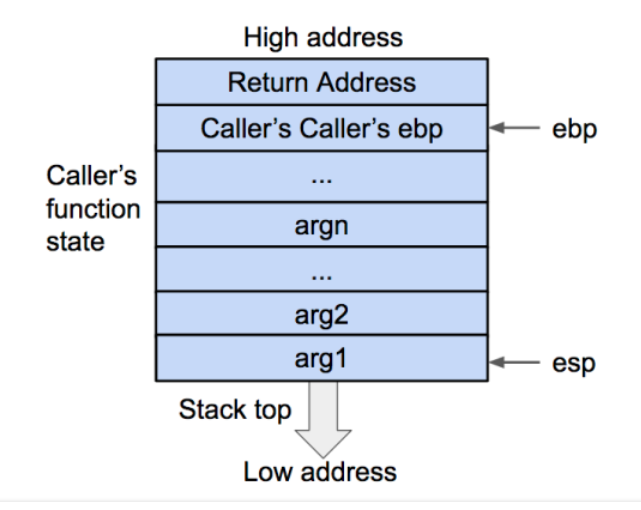
首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。
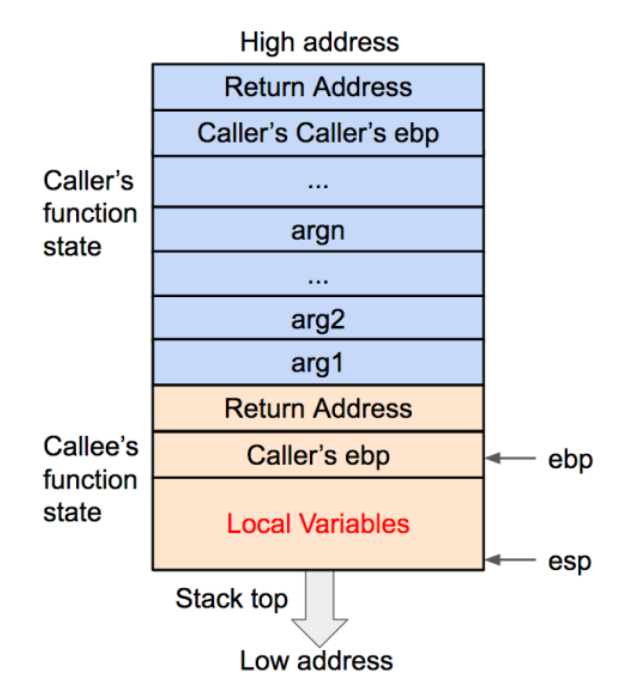
然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到 EBP寄存器内。这样调用函数(caller)的 EBP(基地址)信息得以恢复。此时栈顶会指向返回地址。
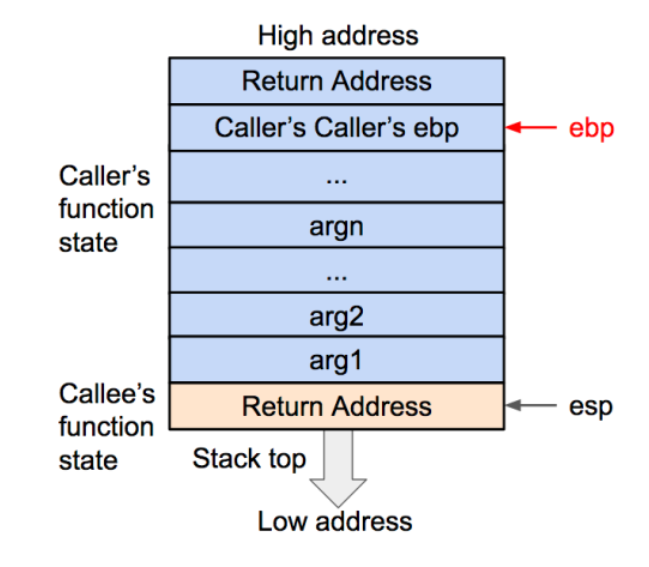
再将返回地址从栈内弹出,并存到 EIP 寄存器内。这样调用函数(caller)的 EIP(指令)信息得以恢复。
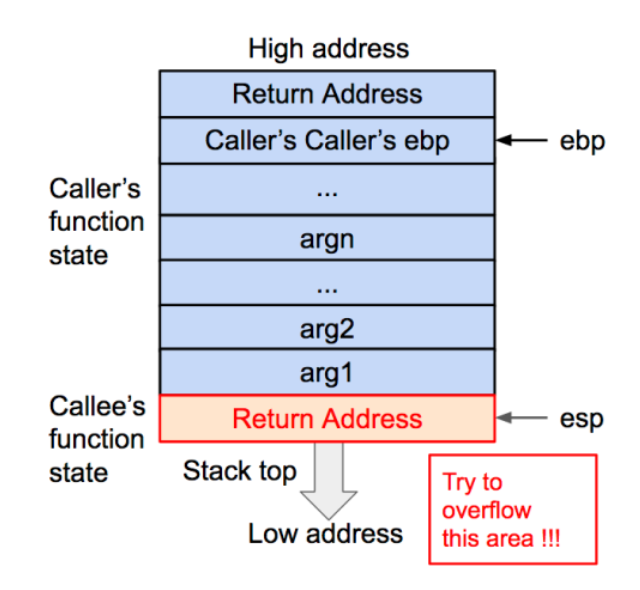
栈溢出
当函数正在执行内部指令的过程中我们无法拿到程序的控制权,只有在发生函数调用或者结束函数调用时,程序的控制权会在函数状态之间发生跳转,这时才可以通过修改函数状态来实现攻击。
我们的目标就是让 EIP 载入攻击指令的地址
在退栈过程中,返回地址会被传给 EIP,所以我们只需要让溢出数据用攻击指令的地址来覆盖返回地址就可以了。
我们也可以在溢出数据内包含一段攻击指令,也可以在内存其他位置寻找可用的攻击指令。
- 我们要做的就是将原本EIP指定的函数在调用时替换为其他函数。
栈溢出技术种类
修改返回地址,让其指向溢出数据中的一段指令(shellcode)
修改返回地址,让其指向内存中已有的某个函数(return2libc)
修改返回地址,让其指向内存中已有的一段指令(ROP)
修改某个被调用函数的地址,让其指向另一个函数(hijack GOT)
shellcode
payload : padding1 + address of shellcode + padding2 + shellcode
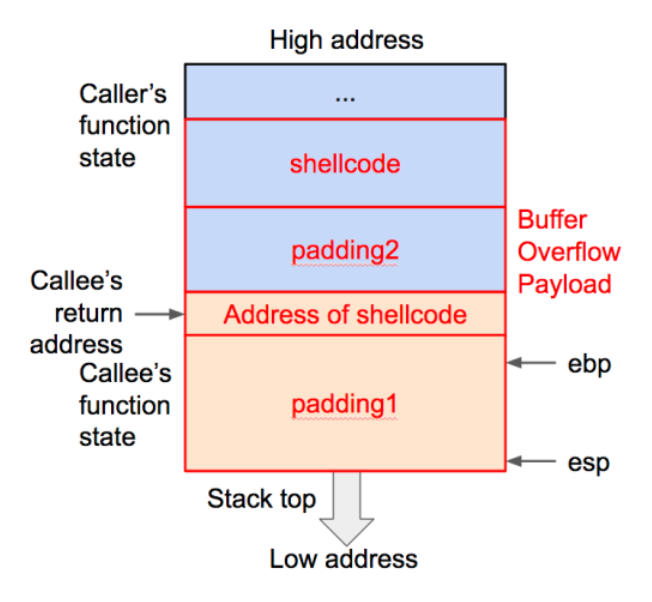
padding1 处的数据可以随意填充(注意如果利用字符串程序输入溢出数据不要包含 “\x00” ,否则向程序传入溢出数据时会造成截断),长度应该刚好覆盖函数的基地址。address of shellcode 是后面 shellcode 起始处的地址,用来覆盖返回地址。padding2 处的数据也可以随意填充,长度可以任意。shellcode 应该为十六进制的机器码格式。
根据上面的构造,我们要解决两个问题。
返回地址之前的填充数据(padding1)应该多长?
我们可以用调试工具(例如 gdb)查看汇编代码来确定这个距离,也可以在运行程序时用不断增加输入长度的方法来试探(如果返回地址被无效地址例如“AAAA”覆盖,程序会终止并报错)。
shellcode起始地址应该是多少?
我们可以在调试工具里查看返回地址的位置(可以查看 EBP 的内容然后再加4(32位机),参见前面关于函数状态的解释),可是在调试工具里的这个地址和正常运行时并不一致,这是运行时环境变量等因素有所不同造成的。所以这种情况下我们只能得到大致但不确切的 shellcode 起始地址,解决办法是在 padding2 里填充若干长度的 “\x90”。这个机器码对应的指令是 NOP (No Operation),也就是告诉 CPU 什么也不做,然后跳到下一条指令。有了这一段 NOP 的填充,只要返回地址能够命中这一段中的任意位置,都可以无副作用地跳转到 shellcode 的起始处,所以这种方法被称为 NOP Sled(中文含义是“滑雪橇”)。这样我们就可以通过增加 NOP 填充来配合试验 shellcode 起始地址。
操作系统可以将函数调用栈的起始地址设为随机化(这种技术被称为内存布局随机化,即Address Space Layout Randomization (ASLR) ),这样程序每次运行时函数返回地址会随机变化。反之如果操作系统关闭了上述的随机化(这是技术可以生效的前提),那么程序每次运行时函数返回地址会是相同的,这样我们可以通过输入无效的溢出数据来生成core文件,再通过调试工具在core文件中找到返回地址的位置,从而确定 shellcode 的起始地址。
解决完上述问题,我们就可以拼接出最终的溢出数据,输入至程序来执行 shellcode 了。

这种方法生效的一个前提是在函数调用栈上的数据(shellcode)要有可执行的权限(另一个前提是上面提到的关闭内存布局随机化)。很多时候操作系统会关闭函数调用栈的可执行权限,这样 shellcode 的方法就失效了,不过我们还可以尝试使用内存里已有的指令或函数,毕竟这些部分本来就是可执行的,所以不会受上述执行权限的限制。这就包括 return2libc 和 ROP 两种方法。
Return2libc
在内存中确定某个函数的地址,并用其覆盖掉返回地址。由于 libc 动态链接库中的函数被广泛使用,所以有很大概率可以在内存中找到该动态库。同时由于该库包含了一些系统级的函数(例如 system() 等),所以通常使用这些系统级函数来获得当前进程的控制权。鉴于要执行的函数可能需要参数,比如调用 system() 函数打开 shell 的完整形式为 system(“/bin/sh”) ,所以溢出数据也要包括必要的参数。下面就以执行 system(“/bin/sh”) 为例,先写出溢出数据的组成,再确定对应的各部分填充进去。
payload: padding1 + address of system() + padding2 + address of “/bin/sh”
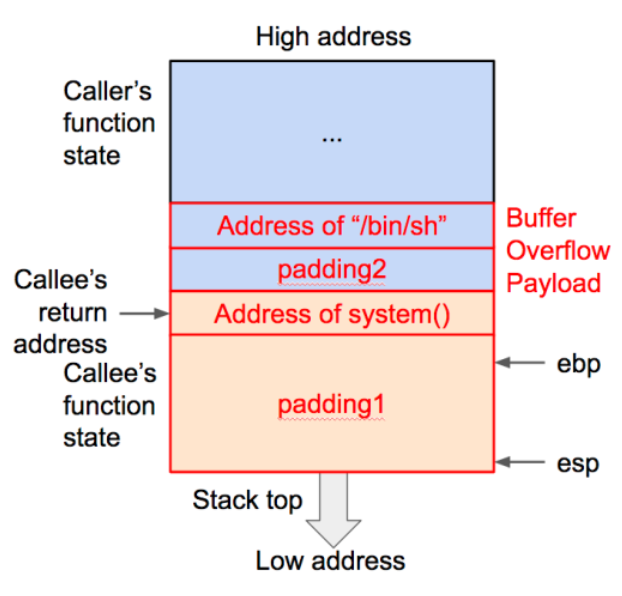
padding1 处的数据可以随意填充(注意不要包含 “\x00” ,否则向程序传入溢出数据时会造成截断),长度应该刚好覆盖函数的基地址。address of system() 是 system() 在内存中的地址,用来覆盖返回地址。padding2 处的数据长度为4(32位机),对应调用 system() 时的返回地址。因为我们在这里只需要打开 shell 就可以,并不关心从 shell 退出之后的行为,所以 padding2 的内容可以随意填充。address of “/bin/sh” 是字符串 “/bin/sh” 在内存中的地址,作为传给 system() 的参数。
根据上面的构造,我们要解决个问题。
返回地址之前的填充数据(padding1)应该多长?
解决方法和 shellcode 中提到的答案一样。
system() 函数地址应该是多少?
要回答这个问题,就要看看程序是如何调用动态链接库中的函数的。当函数被动态链接至程序中,程序在运行时首先确定动态链接库在内存的起始地址,再加上函数在动态库中的相对偏移量,最终得到函数在内存的绝对地址。说到确定动态库的内存地址,就要回顾一下 shellcode 中提到的内存布局随机化(ASLR),这项技术也会将动态库加载的起始地址做随机化处理。所以,如果操作系统打开了 ASLR,程序每次运行时动态库的起始地址都会变化,也就无从确定库内函数的绝对地址。在 ASLR 被关闭的前提下,我们可以通过调试工具在运行程序过程中直接查看 system() 的地址,也可以查看动态库在内存的起始地址,再在动态库内查看函数的相对偏移位置,通过计算得到函数的绝对地址。
最后,“/bin/sh” 的地址在哪里?
可以在动态库里搜索这个字符串,如果存在,就可以按照动态库起始地址+相对偏移来确定其绝对地址。如果在动态库里找不到,可以将这个字符串加到环境变量里,再通过 getenv() 等函数来确定地址。
解决完上述问题,我们就可以拼接出溢出数据,输入至程序来通过 system() 打开 shell 了。
以上两种方案都需要操作系统关闭布局随机化(ASLR)
两种方法都是通过覆盖返回地址来执行输入的指令片段(shellcode)或者动态库中的函数(return2libc)。需要指出的是,这两种方法都需要操作系统关闭内存布局随机化(ASLR),而且 shellcode 还需要程序调用栈有可执行权限。
下面的另外两种执行方法,其中有可以绕过内存布局随机化(ASLR)的方法,敬请关注。